
截止到2020年7月27日,新型冠狀病毒肺炎(COVID-19)疫情已波及全球215個國家和地區,報告累計確診病例1637.4w例,死亡6.5w例,而實際上感染人數和死亡人數可能還要高的多。 疫情擴散導致對醫院床位的需求大幅增加,醫療資源和設備出現嚴重短缺,為了減輕醫療係統的負擔,同時也為患者提供盡可能更好的醫療服務,需要對COVID-19進行準確的診斷,並對疾病的預後情況進行有效的評估。 如果
截止到2020年7月27日,新型冠狀病毒肺炎(COVID-19)疫情已波及全球215個國家和地區,報告累計確診病例1637.4w例,死亡6.5w例,而實際上感染人數和死亡人數可能還要高的多。
疫情擴散導致對醫院床位的需求大幅增加,醫療資源和設備出現嚴重短缺,為了減輕醫療係統的負擔,同時也為患者提供盡可能更好的醫療服務,需要對COVID-19進行準確的診斷,並對疾病的預後情況進行有效的評估。
如果能夠基於患者入院的基本特征,提前預測患者未來的預後是好還是差,就可以對患者進行分級,進而將有限的醫療資源進行合理的分配,這就需要用到我們在臨床研究中經常用到的一個方法--預測模型。
針對COVID-19的預測模型,從基礎的評分係統到高級的機器學習模型,各種各樣的模型層出不窮。2020年7月1日,BMJ期刊發表了一篇係統綜述《Prediction models for diagnosis and prognosis of covid-19:systematic review and critical appraisal》,對現有研究提出的COVID-19預測模型進行了係統評價和批判性評估。

研究人員通過計算機檢索了2020年1月3日至5月5日在Pubmed、Embase、BioRxiv、medRxiv、arXiv等多個數據庫中,公開發表的或同行審議的或預印本的研究論文,重點關注三種類型的預測模型:對COVID-19嚴重程度或疑似病例確診為COVID-19進行預測的診斷模型,對COVID-19感染病程進行預測的預後模型,以及在一般人群中識別出COVID-19感染高危人群的預測模型。
研究人員使用基於CHAMS(預測模型研究係統綜述的批判性評估和數據提取)核對表和PROBAST(預測模型偏倚風險評估工具)的標準化數據提取表來對預測模型進行評價,並按照PRISMA(係統綜述和Meta分析優先報告條目)和TRIPOD(個體預後或診斷的多因素預測模型報告聲明)報告規範對評價結果進行了報告。
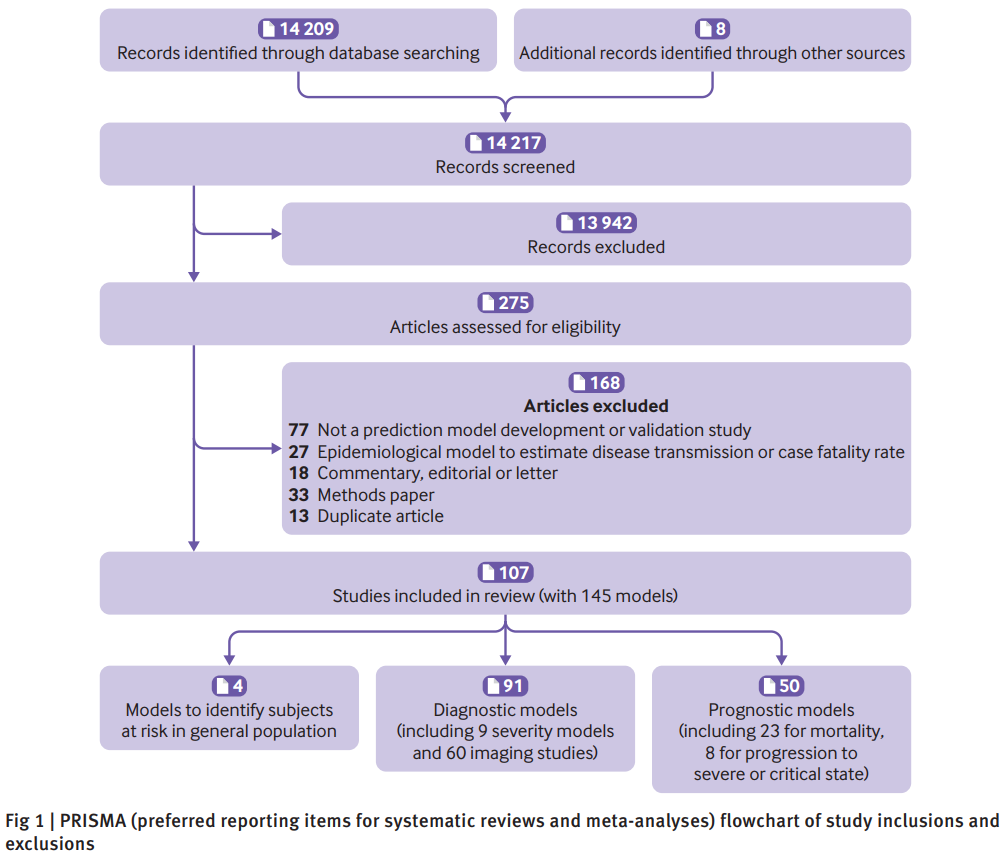
研究人員一共檢索到了14209篇研究論文,並從其他途徑獲取了8篇論文,通過對題目進行篩選,剩餘275篇進行摘要和全文篩選,最終有107篇論文145個預測模型符合納入標準,見圖1所示。
1、高危人群鑒別模型
對於一般人群發生COVID-19風險的預測模型共有4項,其中有3個模型均來自同一性研究,使用非結核性肺炎、流感、急性支氣管炎或上呼吸道感染的住院患者作為替代結局,而沒有使用任何COVID-19的病例數據信息。預測因素包括:年齡、性別、既往住院史、共患病以及健康的社會決定因素,C統計量分別為0.73、0.81和0.81。第4個模型是通過對戴口罩的人麵部的熱視頻進行深度學習來確定是否有異常呼吸,但也與COVID-19無關。
2、診斷模型
對於COVID-19疑似病例中確診為COVID-19的診斷模型共有22項,大多數模型是針對疑似COVID-19的患者。研究報告的C統計量範圍在0.65-0.99之間。報告最多見的診斷預測因素有:流感樣體征和症狀(如寒顫、疲勞)、影像學特征(如CT肺炎體征)、年齡、體溫、淋巴細胞計數和中性粒細胞計數。
對於COVID-19嚴重程度的預測模型共有9項,其中8項是成人模型,C統計量在0.80-0.99之間,另1項是針對兒童患者的研究。報告最多見的診斷預測因素有:共患病、肝酶、CRP、影像學特征和中性粒細胞計數。
有60項預測模型都提出基於影像學的圖像結果可以支持COVID-19的診斷,或監測其病情進展過程。大多數研究都采用了胸部CT檢查或X射線檢查,還有一些研究使用了肺部超聲等,C統計量在0.81-0.99之間。
3、預後模型
對於預測COVID-19確診患者的預後模型共有50項,但是多數對於模型的使用(如什麼時間使用、使用對象是誰)並沒有明確的描述,預測範圍從1天到30天不等,往往也沒有具體說明。在這些模型中,有23項評估的是死亡風險,8項評估的是疾病進展到嚴重或危機狀態的風險,剩下的模型評估的是其他結局事件的風險,例如康複、住院時間、入住ICU、氣管插管、機械通氣時間及急性呼吸窘迫綜合征。
報告最多見的診斷預測因素有:共患病、年齡、性別、淋巴細胞計數、CRP、體溫、肌酐和影像學特征。死亡預測模型的C統計量在0.68-0.98之間,疾病進展預測模型的C統計量在0.73-0.99之間,其他結局預測模型的C統計量在0.72-0.96之間。
4、偏倚風險
研究人員使用PROBAST工具對所有發表的研究偏倚風險進行了評估,結果顯示所有的研究都存在很高的偏倚風險,這就意味著這些預測模型在實際的應用過程中,其預測能力可能要比研究中報告的低很多,因此有理由認為當這些預測模型應用到研究人群之外時,是非常不可靠的,沒有一個可以推薦到臨床中進行使用。
PROBAST工具共包括“研究對象”、“預測因子”、“臨床結局”、“數據分析”四個領域共20項問題。在這107項研究中有53項研究在“研究對象”這一領域有很高的偏倚風險,這表明研究中的參與者可能不能代表模型的目標人群;有15項研究在“預測因子”領域存在較高的偏倚風險,表明預測因子在模型預期的使用時間內不可獲得,沒有明確的定義,或者受結局測量的影響;有19項研究,由於使用主觀或替代結局(例如,非COVID-19導致的嚴重呼吸道感染),有理由擔心結局測量所引起的偏差。
最令人擔心的是,除1項研究外,其餘研究在“數據分析”領域都存在非常高的偏倚風險,許多研究的樣本量較少,這導致數據過度使用的風險增加,特別是在使用複雜建模策略的情況下。數據分析存在的問題涉及方方麵麵,例如沒有報告模型的預測能力,沒有報告模型的校準指標,或檢查校準的方法不是最好的,外部驗證的數據集可能不能代表目標人群等等。

預測模型的主要目的是支持醫療決策,因此,確定預測模型的目標人群顯得至關重要,具有代表性的數據庫才有可能被開發為預測模型並進行驗證。同時,目標人群必須進行清晰的描述,從而可以來評估開發或驗證模型的性能,以及在使用模型時能夠清楚知道所應用的目標人群。但是不幸的是,目前的COVID-19預測模型研究往往缺乏對研究人群的充分描述,這使得使用者對模型的適用性產生了懷疑。
研究人員建議,模型開發者們都應該遵循TRIPOD報告規範來提高預測模型的質量。在開發新的預測模型時,建議在以前的文獻和專家意見的基礎上選擇預測因素,而不是以純數據驅動的方式選擇預測因素。目前供過於求的不可靠的驗證模型對臨床實踐沒有任何用處,未來的研究應該更集中於驗證、比較、改進和更新有前景的現有預測模型。
參考文獻:
BMJ2020;369:m1328(http://dx.doi.org/10.1136/bmj.m1328)

 我要跟帖
我要跟帖copyright©醫學論壇網 版權所有,未經許可不得複製、轉載或鏡像
京ICP證120392號 京公網安備110105007198 京ICP備10215607號-1 (京)網藥械信息備字(2022)第00160號



